

在Hive中hiveudafudf区别,函数hiveudafudf区别的运用是其强大功能的重要组成部分函数大致可以分为三个类别用户自定义函数UDF用户定义聚合函数UDAF以及用户定义表生成函数UDTFUDF的特点是处理单行数据hiveudafudf区别,产生单行结果UDAF则针对多行数据hiveudafudf区别,同样返回单行汇总结果而UDTF则接收单行输入hiveudafudf区别,但能输出多行或多列数据每个Hive函数。
用户自定义函数分类UDF用于执行简单的计算或转换,如自定义的round函数UDAF用户定义的聚合函数,用于执行聚合操作,如count, sum,以及数据去重UDTF用户定义的表生成函数,生成类似表的结果,如explode函数,实现一行数据转换为多行应用案例手机号加密UDF通过明确需求编写逻辑打包上传。
文章深入讲解了Hive的函数使用,包括关系运算数值计算条件函数日期函数和字符串函数等基础函数,以及高级函数如窗口函数行转列列转行自定义函数UDFUDTF和UDAF等其中,窗口函数开窗函数在解决TopN问题时特别有用文章最后介绍了如何使用Hive的Shell进行操作,并推荐了技术交流群和关注。
UDAFUDTF与Lateral view是Hive中的关键函数,分别用于聚合计算表生成以及数据变换UDAF用户定义的聚合函数主要与group by语句配合使用,进行数据聚合UDTF用户定义的表生成函数则是重点,其中explode函数常与split一起使用,参数为Map时展示基础效果,posexplode与explode相似,但额外带有一个单独。
注释处理元数据存储函数使用查询优化等方面的知识此外,还有关于Hive与传统关系型数据库的对比Hive的内部表与外部表的区别数据仓库分层的重要性解决Hive小文件问题的方法保存元数据的多种方式UDFUDAF和UDTF的区别Hive底层与数据库交互原理Hive中的join操作以及优化策略等内容。
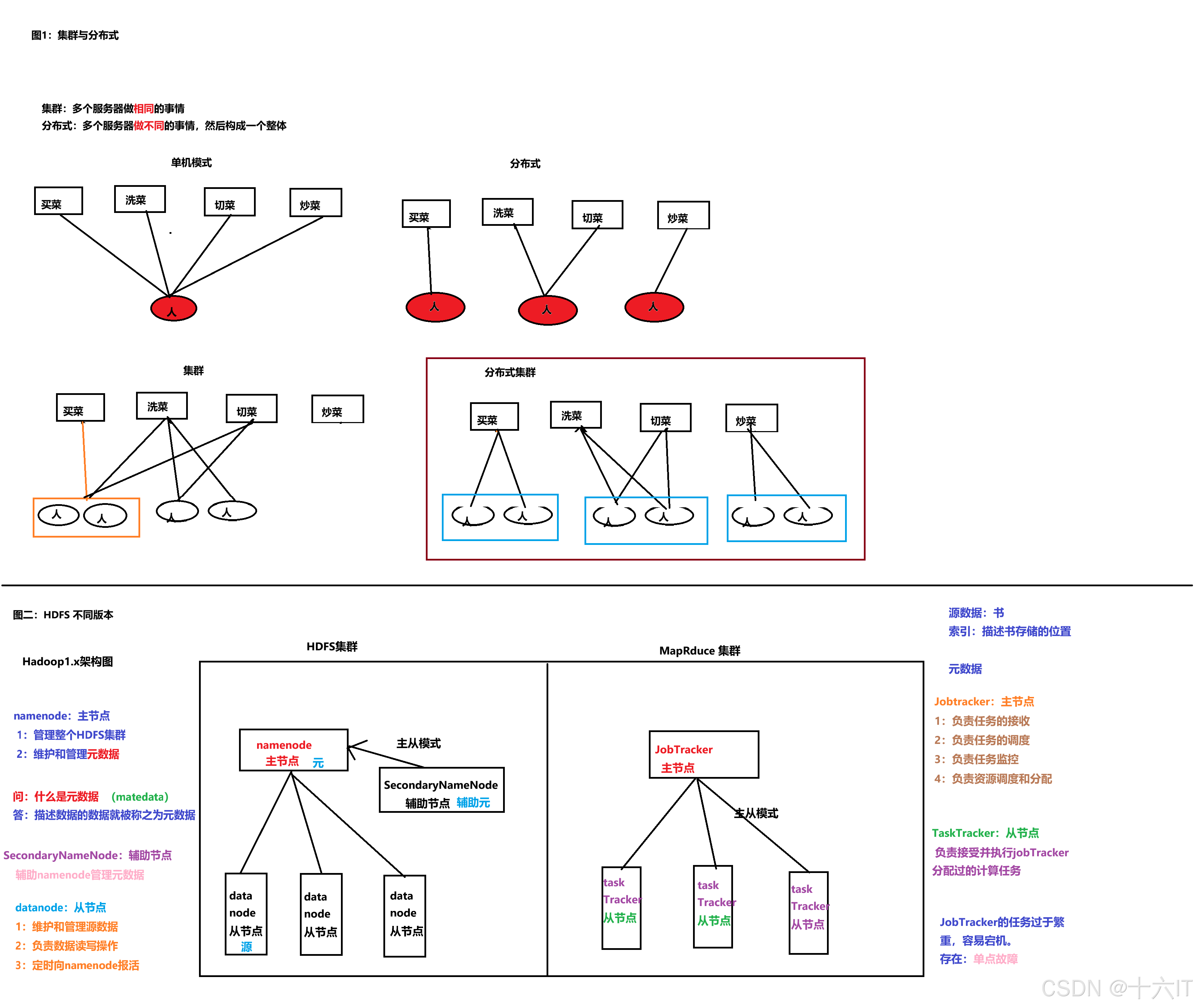
九Hive中用户自定义函数实现步骤回答构建用户自定义函数需继承UDFUDAF或UDTF,实现特定方法,打包为jar文件,注册到Hive环境中,通过create function注册并使用十Hive中表的存储格式回答Hive支持存储格式包括TEXTFILESEQUENCEFILEORC与PARQUET列式存储和行式存储各有特点,列式存储在查询。

构建用户自定义函数步骤包括继承UDFUDAFUDTF,实现特定方法,打包为jar文件,注册函数等用户自定义函数分为UDFUDAFUDTF三种类型十Hive中表的存储格式有哪些Hive支持的存储格式有TEXTFILESEQUENCEFILEORCPARQUET列式存储和行式存储的区别在于查询性能和压缩效率各存储格式特点包括。
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取转化加载,这是一种可以存储查询和分析存储在Hadoop中的大规模数据的机制hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行Hive的优点是学习成本低,可以通过类似SQL语句实现。
通过Fetch task直接获取数据Hive函数UDFUDAFUDTF的区别UDF单行输入单行输出UDAF多行输入单行输出UDTF单行输入多行输出理解Hive桶表桶表通过哈希值将数据分到不同文件存储,用于抽样查询物理上,每个桶是一个文件,对应一个Reduce任务,专用于抽样,不用于日常数据存储。
hive与impala在查询分析这部分,hive明显的支持程度要比impala高,提供了很多内部函数,并且支持UDAF,UDF的方式 从数据库特性角度来看,hive与hbase的对比,hive不能修改数据,只能追加的方式,hbase允许增加和删除数据,hive不支持索引,impala和hive都是没有存储引擎的,hbase算是有自己的存储引擎在使用层面。
在Flink三层API中,Table API位于最顶层,用户可以使用SQL语法编写代码,对初学者友好,但受限于预定义函数为满足灵活需求,用户需自定义如Hive的UDFUDTFUDAF,Flink将其分别对应为Scalar FunctionsTable Functions和Aggregate Functions二效果预览 预览结果如上,通过UDTF函数实现了将行数据以列形式。
基于 Hive 开发的 UDF 需将 Jar 包放置于指定目录,并执行动态注册指令用户可将指令放入单独的 notebook,以便在需要时通过 include 语法引用关于 UDF 不支持 Python 的原因,Byzer 提供了更高效的方式如 Byzerpython,用户可使用 Python 实现功能,如加载和处理大量图片Python 回调函数与 Ray。
求解中位数时,通常在Python中利用内置函数简便实现如求解数组的中位数,可直接调用numpy库的median函数,代码简洁高效然而,Hive中并未提供直接的中位数计算函数,但提供了两个用于计算百分位数的UDAF用户定义聚合函数percentile和percentile_approx官方文档中介绍,percentile函数精确计算某一百分。
考虑到Hive本身不支持Roaring Bitmap数据类型,可以将其序列化为`binary`类型使用在函数体系方面,需要实现一系列的UDF和UDAF函数,如`bitmap_count``bitmap_and``bitmap_not``bitmap_union``bitmap_contains``range_bitmap``bitmap_to_array``array_to_bitmap`等,以支持bitmap。
它还提供了一系列的工具进行数据提取转化加载,用来存储查询和分析存储在Hadoop中的大规模数据集,并支持UDFUserDefined FunctionUDAFUserDefined AggregateFunction和UDTFUserDefined TableGenerating Function,也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。




还没有评论,来说两句吧...